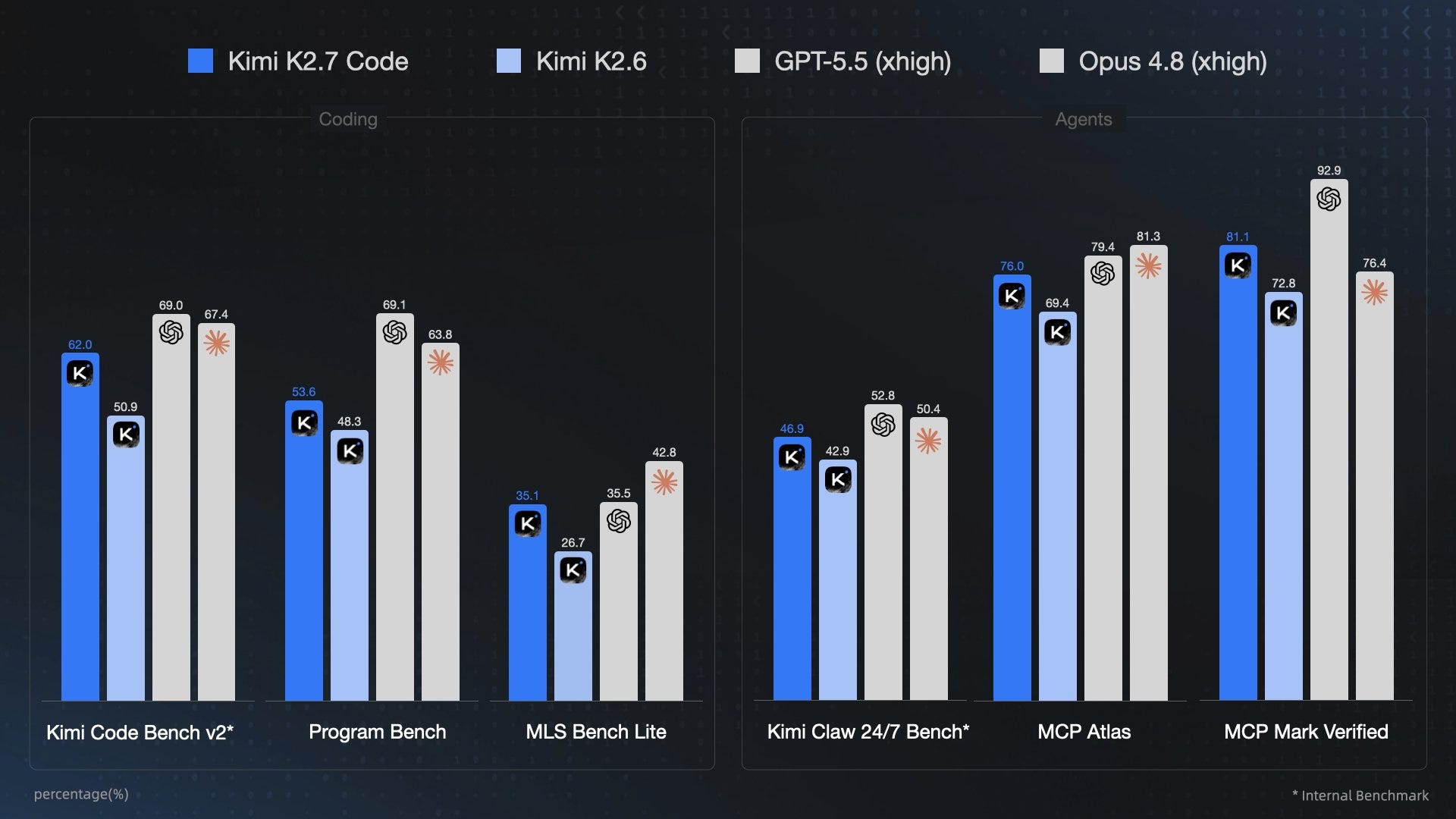
A corrida para desenvolver modelos de linguagem capazes de escrever código está mais intensa do que nunca, e uma nova rodada de testes colocou à prova três nomes promissores do universo open source: o Kimi K2.7 Code, o GLM 5.2 e o MiniMax M3. Este último, inclusive, acaba de ter seus pesos abertos, mas ainda se mostra um desafio para rodar em configurações domésticas.
Os resultados desses modelos são medidos em um benchmark que simula uma tarefa de programação complexa. Enquanto a indústria de IA lida com um gargalo crescente na infraestrutura de data centers, a performance desses modelos locais ganha um novo contorno. Afinal, modelos open source rodando na máquina do desenvolvedor poderiam aliviar a pressão sobre os servidores em nuvem? A resposta, por enquanto, está em aberto.
Como funciona o benchmark, afinal?
Para quem está chegando agora neste debate, o benchmark em questão submete cada modelo a um desafio ambicioso: construir, do zero e de forma autônoma, um aplicativo de chat similar ao ChatGPT. A plataforma escolhida é Rails 8, com a integração de RubyLLM, Hotwire e Docker, além de exigir a inclusão de testes e CI (Continuous Integration). A avaliação é feita por uma rubrica de oito dimensões, com notas de 0 a 100, classificadas em tiers A, B, C ou D.
Este teste não é um evento isolado, mas parte de uma série de avaliações que acompanham a evolução dos LLMs. Testes anteriores incluíram o Benchmark canônico de Maio (Parte 3), que estabeleceu a metodologia, e a avaliação do DeepSeek destravado com DeepClaude. Também foram publicadas análises do Grok 4.3, MiniMax M3 e Opus 4.8 – sendo que o MiniMax M3 estreou via nuvem – e do Fable 5.
A saga dos data centers ganha um novo capítulo com a SpaceX
A escassez de infraestrutura para suportar a demanda crescente por IA tem sido um tema recorrente. A construção de data centers se tornou um verdadeiro gargalo, com quase metade dos projetos planejados nos EUA para 2026 sendo adiados ou cancelados. O motivo? A falta de transformadores e componentes elétricos, que enfrentam filas de entrega de até três anos.
Nesse cenário, um desenvolvimento financeiro recente traz um novo elemento à equação. A SpaceX abriu seu capital naquele que se tornou o maior IPO da história de Wall Street. A empresa conseguiu uma avaliação de US$ 1,77 trilhão, com uma demanda de investidores que superou os US$ 250 bilhões, contra os US$ 75 bilhões inicialmente previstos. O argumento central para essa valuation astronômica foi o plano da empresa de construir infraestrutura de computação para IA.
“556 milhões de ações a US$ 135, avaliação de US$ 1,77 trilhão, com mais de US$ 250 bilhões de demanda de investidor”
A estratégia da SpaceX inclui o lançamento dos satélites AI1, descritos como “data centers orbitais”, a partir do final de 2027. A empresa já teria fechado acordos de computação com a Anthropic e o Google. A expectativa é que IPOs de empresas como a Anthropic e a OpenAI seguirão esse caminho, com o objetivo comum de acelerar a disponibilidade de capacidade de processamento, que atualmente é insuficiente.
É nesse contexto que a relevância dos LLMs open source se destaca. A possibilidade de que uma parte das tarefas de IA possa ser executada localmente, na máquina do desenvolvedor, representaria uma diminuição significativa na carga sobre os data centers centralizados. No entanto, o autor ressalta que essa é uma possibilidade futura, e não uma realidade presente. O benchmark serve justamente para medir a distância entre o potencial e a aplicação prática desses modelos.
Programação “séria” ainda pede Claude Opus 4.8 ou GPT 5.5
Apesar do avanço dos modelos open source, a recomendação para projetos de programação que exigem seriedade e robustez ainda recai sobre o Claude Opus 4.8 ou o GPT 5.5, especialmente quando utilizados dentro de plataformas como o Claude Code ou OpenCode. O motivo é que os modelos open source, em sua maioria, ainda não alcançam o nível necessário para conduzir projetos complexos do início ao fim, especialmente em sessões de codificação mais longas.
A limitação se deve, em grande parte, ao tamanho reduzido desses modelos e suas janelas de contexto restritas. Para uma programação de alto nível, o autor estabelece um mínimo de 200 mil tokens de contexto como o ideal, algo que a maioria dos modelos open source não consegue entregar com a qualidade esperada. Consequentemente, a maior parte da oferta open source avaliada neste benchmark se posiciona no Tier B ou abaixo.